
Ok, devi unire la tabella dei clienti con quella degli ordini selezionando solo i clienti che non hanno effettuato ordini e non sai come fare? È molto semplice cavarsela in questa e molti altre situazioni simili utilizzando l’opzione IN= dei dataset che vuoi unire con lo statement MERGE. Come si fa? Ti illustro 7 esempi.
Supponiamo di avere due tabelle:
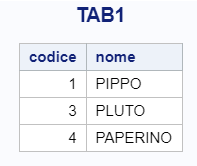

Nella prima sono registrati i nomi di alcuni dei nostri migliori amici, nella seconda qualche informazione anagrafica che li riguarda.
Avrai forse notato che le due tabelle hanno una variabile in comune: “CODICE”. Utilizzeremo proprio questa variabile come chiave per unire i due dataset per mezzo dello statement MERGE.
Prima di cominciare, occorre fare due precisazioni. Quando vogliamo utilizzare lo statement MERGE per unire due (o più dataset) per mezzo di una chiave in comune occorre che:
- tutti i dataset siano ordinati per quella chiave (oppure abbiamo un indice su quella chiave…ma di questo parleremo in un altro post…😉 ). Se così non è, occorre ordinarli prima di procedere ad unirli.
- la variabile utilizzata per come chiave deve avere lo stesso in tutti i dataset. Se così non è occorre rinominarla prima di effettuare il merge.
I nostri due dataset soddisfano entrambe le condizioni quindi siamo pronti per cominciare con i nostri esperimenti.
Vogliamo utilizzare lo statement MERGE per unire le due tabelle e selezionare…
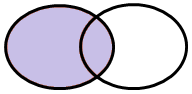
Caso 1 – Tutte le osservazioni appartenenti a TAB1
Tecnicamente, parliamo di LEFT OUTER JOIN in quanto desideriamo che il MERGE restituisca tutte le chiavi presenti nella TAB1 (…che metteremo “a sinistra” nell’elenco delle tabelle da unire, di qui il termine LEFT) indipendentemente dal fatto che siano presenti o meno nella TAB2. Possiamo ricorrere ai digrammi di Venn per dare una rappresentazione visuale a questo concetto:
Bene, siamo fortunati, perché realizzare questa cosa in SAS è straordinariamente facile grazie all’utilizzo combinato dello statement MERGE, dell’opzione IN= e di un istruzione IF.
Ecco il codice SAS da utilizzare in un caso come questo:
data TABELLA_UNITA; merge tab1 (IN = A) tab2; by codice; IF A; run;
e questo è il risultato:
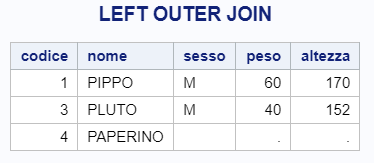
Come vedi, nella tabella di output sono presenti tutte le chiavi presenti nella TAB1 (i codici 1, 3 e 4) indipendentemente dal fatto che siano presenti o meno nella TAB2. PAPERINO, ad esempio, non è presente in TAB2 ma è comunque presente nella tabella finale…ma, ovviamente, senza informazioni anagrafiche annesse.
Viceversa, avendo chiesto tutte le osservazioni appartenenti a TAB1, il codice 2, presente in TAB2 ma assente in TAB1, non risulta nella tabella finale.
Ora, analizziamo velocemente il codice per capire in che modo è stato ottenuto questo risultato.
Avrai notato che nello statement MERGE in corrispondenza di TAB1 ho inserito un’opzione (IN = A). In questo modo, ho “istruito” SAS su quali fossero le osservazioni “appartenenti” al dataset TAB1. L’opzione IN = A, infatti, ha fatto sì che SAS si creasse nel PDV, una variabile temporanea A che assume il valore 1 in corrispondenza delle osservazioni di TAB1, il valore 0 altrimenti.
La variabile A è, come detto, temporanea (infatti non ho dovuto “dropparla” nell’ambito del passo di data) e, inoltre, avrei potuto chiamarla in qualsiasi altro modo rispettoso della naming convention di SAS per i nomi delle variabili. Diciamo che A, in questo caso, è un nome di variabile adeguato per un programmatore pigro come me che ama scrivere codici “sintetici” 😊.
Fatto questo, un paio di righe di codice più sotto, ho potuto sfruttare un IF subsetting per selezionare le osservazioni appartenenti a TAB1 (e per le quali A = 1).
Infatti, scrivere:
IF A;
equivale a scrivere:
IF A = 1;
e anche, volendo essere più “espliciti”, a scrivere:
IF A = 1 THEN OUTPUT;
il ché è come dire a SAS: “scrivi nel dataset di output solo le osservazioni per le quali la variabile A = 1“, ossia quelle appartenenti a TAB1.
OK, se tutto è chiaro fin qui, affrontare gli altri casi possibili sarà un passeggiata…proseguiamo.
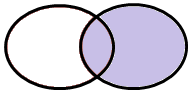
Caso 2 – Tutte le osservazioni appartenenti a TAB2
Tecnicamente, parliamo di RIGHT OUTER JOIN in quanto desideriamo che il MERGE restituisca tutte le chiavi presenti nella TAB2 indipendentemente dal fatto che siano presenti o meno nella TAB1:
Anche in questo caso, sulla falsariga del precedente, utilizzeremo l’opzione IN = in combinazione con un IF subsetting, per ottenere il risultato desiderato:
data TABELLA_UNITA; merge tab1 tab2 (IN = B); by codice; IF B; run;
e questo è il risultato:
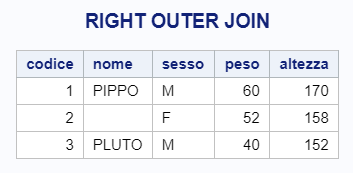
Come vedi, nella tabella di output sono presenti tutte le chiavi presenti nella TAB2 (i codici 1, 2 e 3) indipendentemente dal fatto che siano presenti o meno nella TAB1. Il codice 2, ad esempio, non è presente in TAB1 ma è comunque presente nella tabella finale…ma, ovviamente, in maniera “anonima”.
Viceversa, avendo chiesto tutte le osservazioni appartenenti a TAB2, PAPERINO, presente in TAB1 ma assente in TAB2, non risulta nella tabella finale.
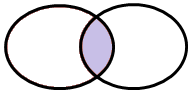
Caso 3 – Tutte le osservazioni appartenenti sia a TAB1 che a TAB2
Qui vogliamo ottenere un INNER JOIN in quanto desideriamo che il MERGE restituisca solo le chiavi presenti in entrambe le tabelle:
Il codice da utilizzare in un caso questo potrebbe essere del tipo:
data TABELLA_UNITA; merge tab1 (IN = A) tab2 (IN = B); by codice; IF A and B; run;
e questo è il risultato che si otterrebbe:

Come vedi, nella tabella di output sono presenti solo le chiavi presenti sia nella TAB1 che nella TAB2 (i codici 1, e 3) .
Andiamo avanti.
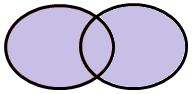
Caso 4 – Tutte le osservazioni che appartengano a TAB1 o a TAB2 indifferentemente
Questo è un caso diverso dal precedente, in quanto vogliamo che nell’output finale siano presenti tutte le osservazioni delle due tabelle di input, indipendentemente dal fatto che appartengano ad una sola di esse o ad entrambe. Tecnicamente si parla di FULL OUTER JOIN :
Il codice da utilizzare in un caso questo potrebbe essere del tipo:
data TABELLA_UNITA; merge tab1 tab2 ; by codice; run;
e questo è il risultato che si otterrebbe:
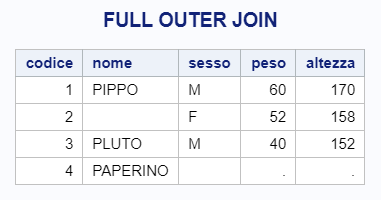
Esattamente quello che volevamo.
Ma, ritorniamo per un attimo al codice utilizzato. Noti qualcosa di “strano”? In effetti, qui non abbiamo utilizzato né l’opzione IN= né l’istruzione IF subsetting.
Beh, non lo abbiamo fatto perché, se ci pensi, non ne abbiamo bisogno: dato che vogliamo in output TUTTE le osservazioni dei dataset di input…non c’è bisogno di “marcarle” in qualche modo particolare (con l’opzione IN=) per poi selezionarle (con un IF subsetting).
Comunque, se proprio avessimo voluto uniformaci al codice scritto negli esempi precedenti, avremmo potuto utilizzare il seguente script:
data TABELLA_UNITA; merge tab1 (IN = A) tab2 (IN = B); by codice; IF A or B; run;
Caso 5 – Tutte le osservazioni che appartengano a TAB1 ma non a TAB2
Questo è un caso simile al primo. Tuttavia qui vogliamo selezionare tutte le osservazioni di TAB1 ad esclusione di quelle che sono presenti anche in TAB2:
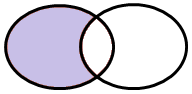
Scommetto che ormai sei sufficientemente esperto per capire che il codice da utilizzare in questo caso è:
data TABELLA_UNITA;
merge tab1 (IN = A)
tab2 (IN = B);
by codice;
IF A AND NOT B;
run;
Questo è il risultato:

Caso 6 – Tutte le osservazioni che appartengano a TAB2 ma non a TAB1
Possiamo dire che questo è il caso “opposto” al precedente. Qui vogliamo selezionare tutte le osservazioni di TAB2 ad esclusione di quelle che sono presenti anche in TAB1:
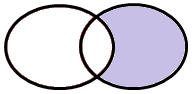
Il codice da utilizzare in questo caso è:
data TABELLA_UNITA;
merge tab1 (IN = A)
tab2 (IN = B);
by codice;
IF B AND NOT A;
run;
Questo è il risultato:

Caso 7 – Tutte le osservazioni che non appartengano sia a TAB1 sia a TAB2
Infine, analizziamo il caso in cui si desideri avere tutte le osservazioni che non appartengano ad entrambe le tabelle TAB1 e TAB2:
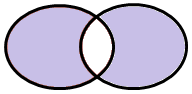
di fatto, si tratta del “complemento” dell’INNER JOIN che abbiamo visto nel caso 3. Il codice da utilizzare in questo caso è:
data TABELLA_UNITA;
merge tab1 (IN = A)
tab2 (IN = B);
by codice;
IF NOT (A AND B);
run;
Se ci fai caso, in effetti, si tratta della “negazione” dell’INNER JOIN visto sopra. Questo è il risultato:

Ecco conclusa la disamina delle varie possibilità di JOIN “a chiave” effettuabili per mezzo dello statement MERGE. I casi che abbiamo visto riguardavano tutti una situazione “semplice” di relazione 1:1 tra le due tabelle. Ovviamente, i concetti espressi valgono anche per situazioni in cui la relazione tra le tabelle è del tipo 1:N…ma anche di questo parleremo in un altro post…
SAS e tutti gli altri nomi di prodotti e servizi di SAS Institute Inc. sono marchi registrati di SAS Institute Inc. negli USA e in altri paesi. ® indica la registrazione negli USA.
