
Siamo fortunati! Quando si parla di datatype, in SAS le cose si fanno estremamente semplici.
Per SAS, infatti, esistono solo due tipi di dati:
- alfanumerici
- numerici
STOP!
Quindi dimenticatevi di termini come : VARCHAR, LONG, ROW, BINARY, NUMBER, INTERGER, DATE, ecc. ecc. perchè, di fatto, in SAS non servono 🙂
Variabili alfanumeriche
Il datatype Character serve per memorizzare informazioni di tipo alfanumerico. Quindi stringhe come:
- ‘Ciao Mamma’
- ‘SRTGNH90R76A988X’
- ‘Via G. Leopardi, 12 – 40999 – Vattelapesca (Roma) – Italia’
- ‘info@programmareinsas.blog’
- ‘M’
- ‘0’
che come vedete, possono contenere sia caratteri alfabetici, sia caratteri “speciali” (punteggiatura, spazi, @, ecc.) sia numeri.
Con questa tipologia di variabili vi potrete sbizzarrire con operazioni di confronto, ordinamento, concatenazione e selezione.
Occupano una porzione di memoria variabile da 1 a 32.767 byte, un byte per ogni digit (lettera, numero, spazio, “carattere speciale”) di cui è composta la stringa in questione.
Per referenziare un valore di una variabile alfanumerica in uno script SAS, è necessario indicarlo tra un coppia di apici singoli (‘ ‘) o doppi (” “). Ad esempio:
if sesso = 'M' then cod_sesso = 1;
oppure
where upcase(descrizione_patologia) contains "DIABETE";
La scelta tra apici singoli o doppi è quasi sempre equivalente. Personalmente, preferisco utilizzare i doppi apici, in quanto se il valore referenziato contiene esso stesso un apice (apostrofo), l’interprete SAS va…per così dire, nel pallone e restituisce un errore bloccante. Ad esempio, questo codice non funziona…:
where cognome = 'D'ambrosio';
questo, invece, sì:
where cognome = "D'ambrosio";
Una puntualizzazione importante. Nel referenziare il valore di una variabile alfanumerica, nell’ambito di una condizione del tipo IF-THEN_ELSE oppure di una clausola WHERE oppure di uno statement di assegnazione del valore stesso alla variabile, occorre ricordarsi che SAS è CASE-SENSITIVE. Quindi, supponendo di dover selezionare da questo dataset solo i record dei maschi:
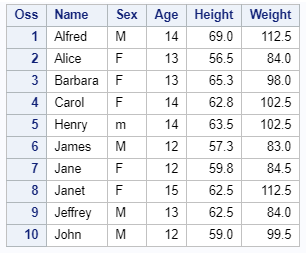
questo codice:
where sex = "M";
selezionerebbe solo i record 1,6,9 e 10. Il record 5 non verrebbe selezionato perché il valore dalla variabile sex è minuscolo!
Un modo per “by-passare” questo tipo di problema, se non si è sicuri al 100% di come sono salvate le informazioni nel dataset, potrebbe essere il seguente:
where upcase(sex) = "M";
In questo modo la clausola è valutata sull’UPCASE della variabile e non sul suo valore ‘originale’. Facendo riferimento all’esempio precedente, in questo caso, anche l’osservazione 5 sarebbe selezionata.
Per le variabili alfanumeriche, il valore mancante (stringa vuota) è visualizzata come uno spazio (blank). Quindi, ipotizzando di voler selezionare tutti i record dei clienti per i quali l’indirizzo di residenza è mancante, potremmo inserire nel nostro programma un codice del tipo:
where indirizzo = " " ;
oppure:
where indirizzo is null;
Variabili numeriche
Il datatype Numeric serve per memorizzare informazioni di tipo…numerico. Quindi cose del tipo:
- 10
- 578665732.189
- -15.2
sulle quali è possibile effettuare qualsiasi tipo di operazione algebrica, oltre a quelle di confronto e ordinamento.
Occupano una porzione di memoria variabile da 3 a 8 byte (default). Il ché non significa che sia possibile memorizzare solo numeri fino a 8 cifre. In 8 byte di memoria è possibile salvare numeri fino a 16 cifre! Infatti il massimo numero intero correttamente rappresentabile è 9.007.199.254.740.992…che, francamente, non saprei neppure come enunciare… 🙂
È evidente, comunque, che il numero di byte che dedichiamo ad una variabile numerica incide sulla precisione dei numeri che con essa desideriamo rappresentare. Quindi, se vogliamo assicurarci il massimo della precisione (se si tratta di numeri reali per i quali sono importanti le cifre decimali, ad esempio), attribuiamo alla variabile 8 byte di memoria. Viceversa, se abbiamo a che fare con numeri interi composti da poche cifre (ad esempio, l’età in anni o l’anno di iscrizione al servizio, o quello di nascita, ecc….) e abbiamo l’esigenza di “risparmiare” spazio sul server avendo magari a che fare con dataset di grandi dimensioni, possiamo attribuire a queste variabili una lunghezza inferiore a 8 (3 o 4 byte possono essere più che sufficienti in questi casi) senza correre il rischio di perdere in precisione.
Quando si ha a che fare con variabili di tipo numerico, il valore mancante (stringa vuota) è visualizzata come un punto (.). Quindi, ipotizzando di voler selezionare tutti i record dei pazienti per i quali l’età è mancante, potremmo inserire nel nostro programma un codice del tipo:
where paz_eta = . ;
oppure, equivalentemente:
where paz_eta is null;
E con questo è tutto. Comunque, se volete approfondire l’argomento potete dare un’occhiata qui.
In uno dei prossimi articoli parleremo delle variabili “data” che, già ve lo anticipo, NON costituiscono un terzo tipo di variabile SAS… 🙂
Alla prossima, quindi.
Stay tuned!
SAS e tutti gli altri nomi di prodotti e servizi di SAS Institute Inc. sono marchi registrati di SAS Institute Inc. negli USA e in altri paesi. ® indica la registrazione negli USA.

2 commenti